ある程度基本事項を学んだら、そこから何ができるのかが気になるところです。
Pythonでおすすめなのが簡単なスクレイピング!今回はPythonを使って、Webページから欲しい情報を取り込んでみましょう。
- 読み込むデータの準備
- データ情報の取得
- 読み取りやすいデータへ
- 実際のページから欲しい情報を解析
- データの保存
- まとめ

読み込むデータの準備
今回はPyCon JP 2018の講演タイトルが見れるWebページ

を用いて、実際にスクレイピングを進めてみましょう。違うWebページを用いたい場合は適宜ページに合わせたコードを実装してくださいね。
※スクレイピングは思いがけずサーバーに負荷をかけてしまうことがありますので、行う際にはサイトでのスクレイピングが許可されているのかを確認の上、行うようにしましょう。
Webデータの取得
まずはデータの取得に必要なrequestsのimportからでしたね。
import requestsそしてあるページからの情報を手に入れるにはrequests.get(サイトのURL)を用います。requestsを出して帰ってきた情報をある変数に代入します。ここではresponseとします。
response = requests.get("https://pycon.jp/2018/event/sessions")これでWebページの情報を得ることができました。
読み取りやすいデータへ
Webページの情報を得ることができましたが、まだ我々の目にはよくわからない情報ですので、理解が可能なHTMLの情報にしてもらいます。
ここで登場するのがBeautifulSoupです。まずはimportをします。
from bs4 import BeautifulSoupそして受け取った情報を、HTML情報にしてもらいましょう!BeutifulSoupの1つ目の引数で解析したい情報を2つ目の引数でどのように解析するのかを指定します。そして解析した情報をsoupという変数に入れます。欲しいのはテキスト情報なので、1つ目の引数にはresponse.contentを指定しています。
soup = BeautifulSoup(response,content, "html.parser")これで人間でも理解が可能な状態になりました!ここまでをとりあえずコードにまとめると。
import requests
from bs4 import BeautifulSoup
response = requests.get("https://pycon.jp/2018/event/sessions")
soup = BeautifulSoup(response.content, "html.parser")実際のページから欲しい情報を解析
ページの準備は整ったので、実際にサイトを見てみましょう。行ってみると下のような感じで、各講演のタイトルや言語、発表時間などがそれぞれまとめられていることがわかります。今回はここからそれぞれのタイトルを抜き出そうと考えます。
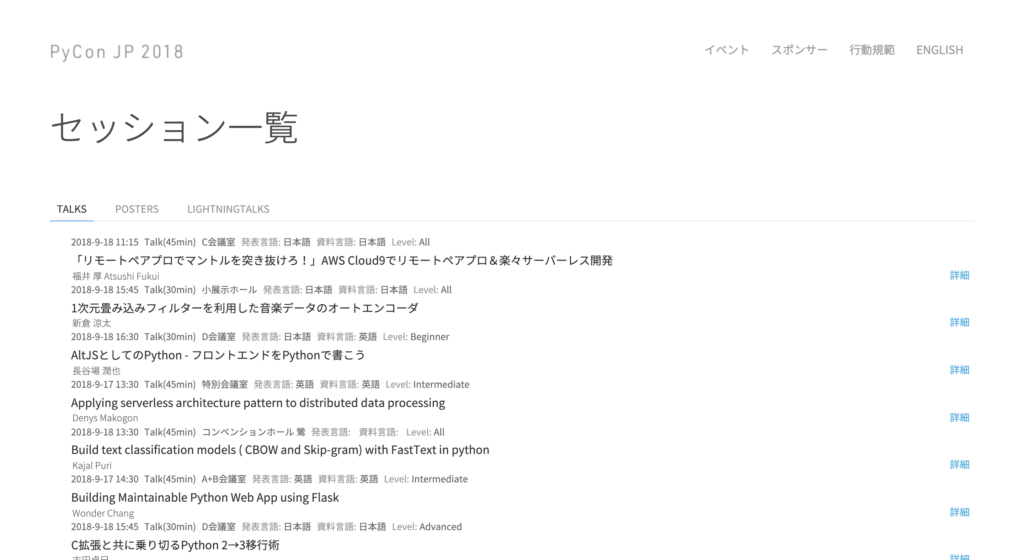
サイト上で右クリックして、検証をクリックすると、画面が分割されて、右側にサイトのHTML情報が掲載されています。
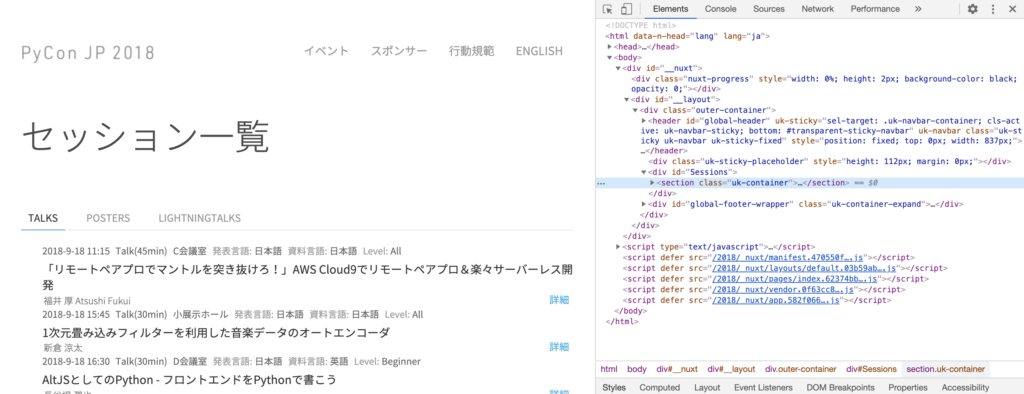
欲しい部分がHTMLでどう表されているのかを簡単に判別する方法として、検証画面での左上をクリックして見る方法があります。

クリックしたら欲しいところにカーソルを持っていき、クリックします。ここでは各講演のタイトルが欲しいのでタイトル上でクリック。
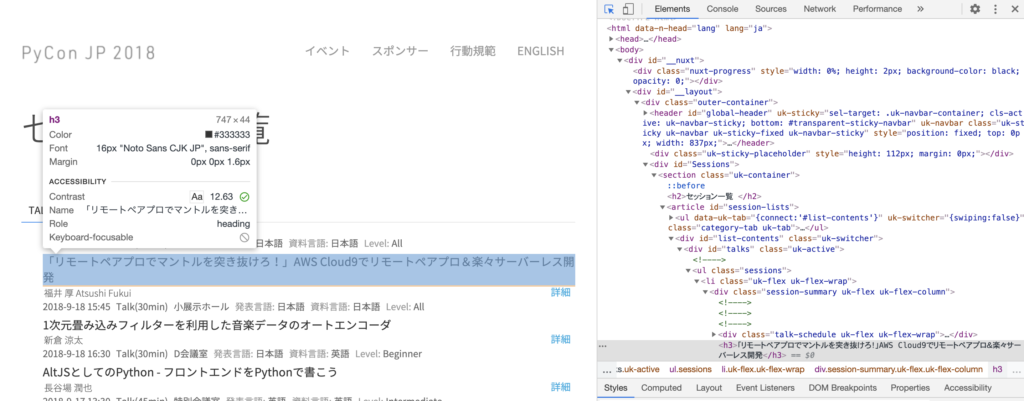
すると、クリックしたところに対応したHTMLでの情報が右側でも選択されるので、ここから情報を抜き出していく手がかりを見つけます。
これをみた感じだと、<h3>タグが各タイトルを表していそうなので、h3を指定しましょう。soup.find_all()で該当する部分をlistで返します、それをtitle_listという変数にいれます、変数名にlistを入れるようにしておくと、この変数って何が入ってるのかがわかりやすいので、癖づけておくのがおすすめです。
title_list = soup.find_all("h3")これで<h3>タグを含む情報をリスト形式で取り込むことができたはずです。
試しに今までやってきたことをインタラクティブシェルで実行し、print(title_list)で確認してみると

と、[ ] で囲まれた、<h3>タグの情報が ” , “で区切られて入っていることがわかります。しっかりとリスト形式で入っていることが確認できましたね。
<h4>データの保存</h4>それではデータを保存しましょう!と言っても保存するだけなら上で得たのをそのまま保存で終わりですが、1行でまとまって保存されてしまうので、データとして成立するために、1つの講演タイトル名で1行で保存してみましょう。
まとめて書くとこうなります。
import csv
for title in title_list:
row=[]
row.append(title.text)
with open("pycontitle.csv", "a")as f:
writer = csv.writer(f, delimiter=",", quotechar='"', quoting=csv.QUOTE_ALL)
writer.writerow(row)最初のfor分でリストを1つずつ取り出しています。2,3行目でrowというリストに各講演タイトルを加えて、4〜6行目でpycontitle.csvというファイルを開き、行ごとにタイトルを加えている操作になります。
コードまとめ
これまでの全てをまとめるとこのようになります。
import requests
from bs4 import BeautifulSoup
import csv
response = requests.get("https://pycon.jp/2018/event/sessions")
soup = BeautifulSoup(response.content, "html.parser")
title_list = soup.find_all("h3")
for title in title_list:
row=[]
row.append(title.text)
with open("pycontitle.csv", "a")as f:
writer = csv.writer(f, delimiter=",", quotechar='"', quoting=csv.QUOTE_ALL)
writer.writerow(row)最後の保存部分に関しては自分がどのようにしたいかによって異なるので、短くしようと思えば短くできますが、この形を把握しておくとかなり使えるので、色々と遊んでみるのがいいかもしれませんね(о´∀`о)
⬇️Pythonを初めたての方にはこちらがおすすめです、ぜひチェックしてみてください⬇︎amazonページに飛びます


コメント